在當今快速迭代的互聯網服務中,微服務架構已成為支撐大規模、高并發應用的主流選擇。網易云音樂作為國內領先的音樂流媒體平臺,其復雜的業務邏輯與龐大的用戶基數對系統的穩定性、可觀測性提出了極高要求。本文將深入探討網易云音樂如何基于 Prometheus 構建一套高效、可靠的微服務監控體系,并分享其在監控廣告設計(此處指監控體系的設計與規劃,而非商業廣告)層面的核心實踐。
一、 監控體系建設的核心挑戰與目標
網易云音樂的微服務架構包含數百個服務,橫跨用戶中心、音樂推薦、社交互動、廣告投放等多個核心模塊。在此背景下,傳統的監控手段難以滿足需求,主要面臨以下挑戰:
- 海量指標采集:服務實例動態擴縮容,指標數據呈爆炸式增長。
- 多維度關聯分析:需要將基礎設施監控、應用性能監控(APM)、業務指標監控進行聯動。
- 實時告警與快速定位:出現故障時,需快速定位到具體服務、實例乃至代碼行。
- 成本與效率的平衡:在保證監控覆蓋度的控制存儲與計算成本。
為此,團隊設定了明確的監控目標:實現從基礎設施到應用邏輯的全棧可觀測,構建事前預警、事中定位、事后分析的閉環能力。
二、 基于 Prometheus 的監控架構“廣告設計”
這里的“廣告設計”意指對監控體系本身進行精心“包裝”與“推銷”,使其在組織內被高效采納和使用,其核心是設計一套用戶(開發、運維、SRE)友好、價值導向的監控方案。
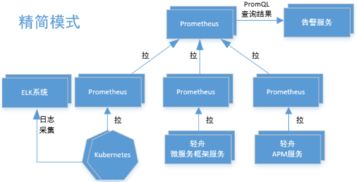
1. 分層采集架構設計
數據采集層:
所有微服務集成 Prometheus Client(如 Java 的 Micrometer),暴露標準化的 metrics 端點。
- 使用
Prometheus Operator在 Kubernetes 集群中自動化管理抓取任務(ServiceMonitor),實現服務的自動發現與監控。
- 對于非 HTTP 服務或中間件(如 MySQL、Redis、Kafka),采用對應的 Exporter 進行指標轉換與暴露。
- 存儲與計算層:
- 核心采用 Prometheus Server 集群分片部署,按業務域(如用戶域、內容域)進行數據分片,降低單點壓力。
- 長期存儲與歷史數據分析遷移至 VictoriaMetrics 或 Thanos,解決 Prometheus 本地存儲的限制,實現數據的長期留存與全局查詢。
- 告警與可視化層:
- 利用
Alertmanager實現告警的分組、去重、靜默及路由,將告警精準推送至釘釘、企業微信、PagerDuty 等平臺。
- Grafana 作為統一的監控數據可視化平臺,預制涵蓋 JVM、HTTP 接口、數據庫、業務黃金指標(流量、錯誤、延遲、飽和度)的儀表盤。
2. 標準化與“產品化”的指標設計(監控的“UI/UX”)
為了讓監控數據易于理解和使用,網易云音樂對監控指標進行了“產品化”設計:
- 命名規范:嚴格遵守
〈namespace〉<em><subsystem></em><metric<em>name>{<label</em>name>=<label_value>}的命名約定,確保指標含義清晰。 - 黃金指標儀表盤:為每個微服務預設四個核心 Grafana 儀表盤:
- 流量:每秒請求數(QPS/RPS)。
- 錯誤:HTTP 錯誤碼比率、業務異常計數。
- 延遲:請求響應時間分位數(P50, P90, P99)。
- 飽和度:系統資源使用率(CPU、內存)、線程池隊列長度、數據庫連接池使用率。
- 業務指標埋點:將關鍵業務動作(如“歌曲播放完成”、“付費成功”)作為自定義指標暴露,實現業務運營與系統性能的關聯分析。
3. 智能告警與故障自愈“廣告”
有效的告警是監控價值的直接體現。網易云音樂的實踐包括:
- 告警分級:根據影響面(全局、局部)和緊急程度(P0-P4)對告警分級,并配置不同的通知渠道與響應流程。
- 避免告警風暴:充分利用 Alertmanager 的抑制規則(Inhibition Rules),當底層基礎設施(如節點宕機)告警觸發時,抑制由此引發的上層應用級海量告警。
- 告警關聯上下文:在告警信息中直接附上相關的 Grafana 儀表盤鏈接、日志查詢鏈接(如鏈接至 Loki 或 ELK)以及可能的故障排查 Runbook,極大縮短了平均故障恢復時間(MTTR)。
三、 實踐成效與未來展望
通過上述基于 Prometheus 的監控體系實踐,網易云音樂獲得了顯著收益:
- 運維效率提升:新服務上線即具備基礎監控能力,故障平均定位時間縮短了 70% 以上。
- 資源成本優化:通過監控數據精準分析服務容量,指導資源彈性伸縮,資源利用率平均提升約 20%。
- 業務保障增強:基于業務指標的監控使技術團隊能更主動地感知業務波動,支撐了多次重大促銷活動的平穩運行。
團隊將繼續在監控領域深化探索:
- 向 OpenTelemetry 標準演進:逐步統一 traces, metrics, logs 的采集標準,構建真正的全棧可觀測性。
- AIOps 賦能:探索基于機器學習的歷史指標分析與異常預測,實現更智能的故障預警與根因分析。
- 可觀測性即代碼:進一步將監控儀表盤、告警規則等通過 GitOps 進行版本化管理,提升變更的安全性與可追溯性。
###
網易云音樂的實踐表明,一個成功的微服務監控體系,不僅需要強大的技術選型(如 Prometheus),更需要像設計產品一樣,從用戶視角出發,進行體系化的“廣告設計”——即通過標準化、產品化、智能化的手段,讓監控數據易于獲取、易于理解、易于行動,最終將其價值無縫融入研發與運維的每一天,成為保障系統穩定與推動業務發展的堅實底座。