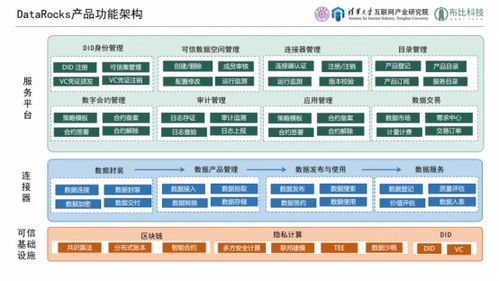
隨著大數(shù)據(jù)時代的到來,數(shù)據(jù)架構經歷了從單體系統(tǒng)到分布式流處理框架的深刻演變。本文將以數(shù)據(jù)處理服務為主線,系統(tǒng)梳理這一變革過程,幫助讀者深入理解數(shù)據(jù)架構的發(fā)展脈絡。
一、單體數(shù)據(jù)架構時代
在早期,數(shù)據(jù)處理多依賴于單體架構,如單一數(shù)據(jù)庫或傳統(tǒng)數(shù)據(jù)倉庫。這類系統(tǒng)將所有數(shù)據(jù)處理邏輯集中在一個應用中,結構簡單、易于部署。隨著數(shù)據(jù)量的激增和實時性要求的提高,單體架構暴露出擴展性差、容錯能力弱、難以支持復雜流處理等瓶頸。例如,在高并發(fā)場景下,系統(tǒng)容易成為性能瓶頸,且故障時可能導致整個服務癱瘓。
二、分布式數(shù)據(jù)架構的興起
為應對單體架構的不足,分布式數(shù)據(jù)架構逐漸普及。這一階段出現(xiàn)了批處理系統(tǒng)(如Hadoop MapReduce)和早期的流處理框架(如Storm)。Hadoop通過分布式存儲和計算實現(xiàn)了海量數(shù)據(jù)的離線處理,但延遲較高;Storm則支持實時流處理,但缺乏精確一次語義和狀態(tài)管理能力。分布式架構提升了擴展性和容錯性,但架構復雜,運維成本增加,且批流分離導致數(shù)據(jù)一致性挑戰(zhàn)。
三、Flink與現(xiàn)代流處理革命
Apache Flink作為新一代流處理引擎,標志著數(shù)據(jù)架構的重大演進。Flink以流處理為核心,統(tǒng)一了批處理和流處理模型,提供低延遲、高吞吐和精確一次語義。其特點包括:
- 狀態(tài)管理:支持有狀態(tài)計算,便于處理復雜事件流。
- 容錯機制:通過檢查點和保存點確保數(shù)據(jù)一致性。
- 靈活部署:可運行于YARN、Kubernetes等環(huán)境,適應云原生趨勢。
Flink廣泛應用于實時數(shù)據(jù)分析、欺詐檢測和物聯(lián)網數(shù)據(jù)處理等領域,推動了數(shù)據(jù)處理服務向實時化、智能化發(fā)展。
四、數(shù)據(jù)處理服務的未來展望
數(shù)據(jù)架構的演變驅動數(shù)據(jù)處理服務不斷升級。未來趨勢包括:
- 湖倉一體化:結合數(shù)據(jù)湖的靈活性和數(shù)據(jù)倉庫的管理能力。
- AI集成:將機器學習與流處理深度融合,實現(xiàn)智能實時決策。
- 云原生優(yōu)化:基于容器和微服務,提升彈性與可觀測性。
從單體到Flink,數(shù)據(jù)架構的演變不僅是技術的迭代,更是業(yè)務需求的映射。企業(yè)需根據(jù)場景選擇合適架構,以構建高效、可靠的數(shù)據(jù)處理服務,賦能數(shù)字化轉型。